Computational performance¶
One of the key design criteria of APyTypes is computational performance. Now, using custom word lengths will always be much slower compared to using word lengths directly supported in hardware. By far. Hence, do not expect APyTypes to compete with, e.g., NumPy in pure computational speed. Also, pure C++-libraries like ac-types and ap-types are template-based. Hence, they know the word length at compile time and can therefore optimize the code. APyTypes must do this dynamically.
Still, there are some ways to improve the performance when running APyTypes. This section will list best practices and expand over time.
To track the computational speed of some selected operations over time, as the code evolves and hopefully improves, see here. These graphs are updated after every commit. However, as they are executed as part of the CI, one can expect a bit of variation. It should still be possible to note significant changes though.
Use arrays if possible¶
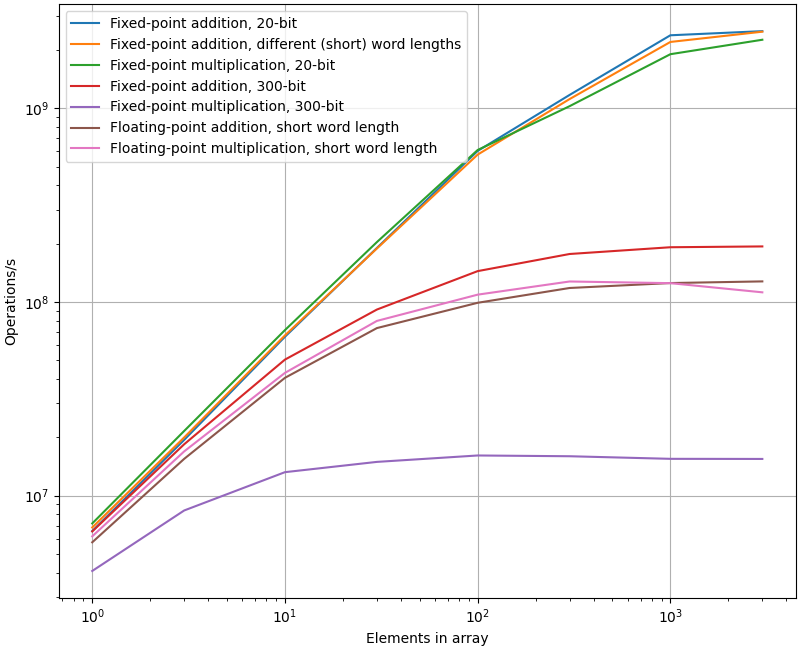
As the overhead of going between Python and C++ is significant for a single number (about 90%), it very much makes sense to use arrays when possible.
See the figure below for the effect of using arrays and the current operation speeds available.
Note
This figure is generated as part of the documentation build and is continuously updated. The actual performance may differ depending on compiler, processor, etc.
In-place shifting for fixed-point¶
Shifting is used to move the binary point of fixed-point numbers. Hence, this will only involve updating the number of integer/fractional bits. However, it may also involve creating a new object, so it is preferred to use in-place shifting if possible.
a = APyFixed(5, bits=6, int_bits=4)
a = a >> 1 # slower
a >>= 1 # faster
Limb-size selection¶
Fixed-point numbers are represented using one or more limbs. The size of the limb is determined by the system APyTypes is compiled against, but will be 64 bits for most “modern” CPUs. This means that all arrays will scale in multiples of 64 bits, so even if you have an array 10-bit fixed-point numbers, each number will be stored as a 64-bit number. This, naturally, has implications on memory use. In addition, all SIMD instructions will operate on 64-bit numbers.
Hence, if you know that you will primarily work with short fixed-point number it may be more efficient to change the limb size to 32 bits. This will save memory for storing arrays and will double the number of operations done in parallel in the SIMD unit.
Note that since APyTypes requires explicit quantization, one should consider the word length of the result. If you work with 20-bit numbers, a multiplication will result in a 40-bit result, and there will be no SIMD-benefit. However, if almost all intermediate results are 32 bits or less, this may give better performance.
To compile APyTypes with 32-bit limbs (on a 64-bit platform), do:
python -m pip install . -v --config-settings=setup-args="-Dlimb_size=32"